
|
|
|
|
|
|
|
|
|
|
|
|
Code [GitHub] |
Paper [arXiv] |
Cite [BibTeX] |
Dataset [HuggingFace] |
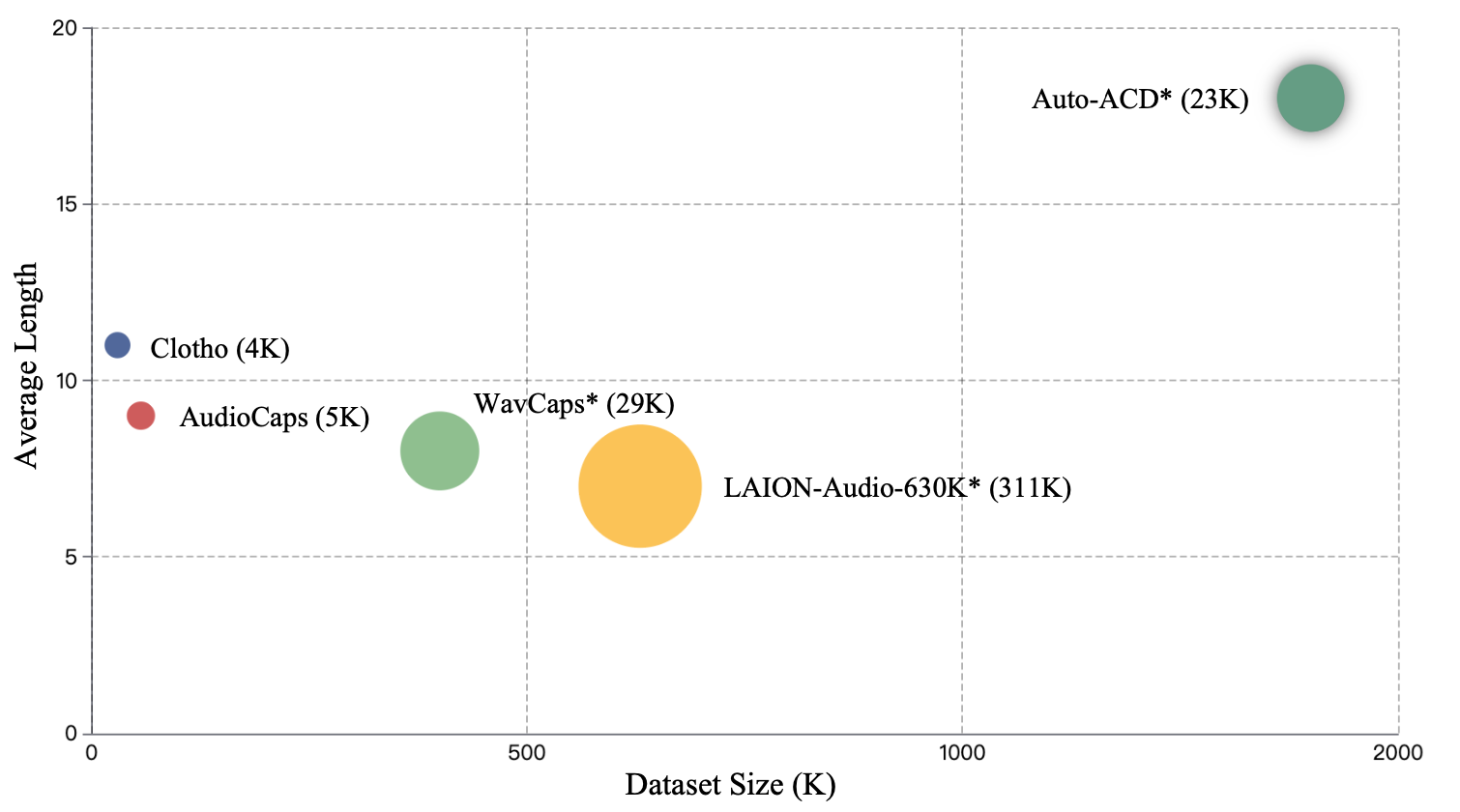
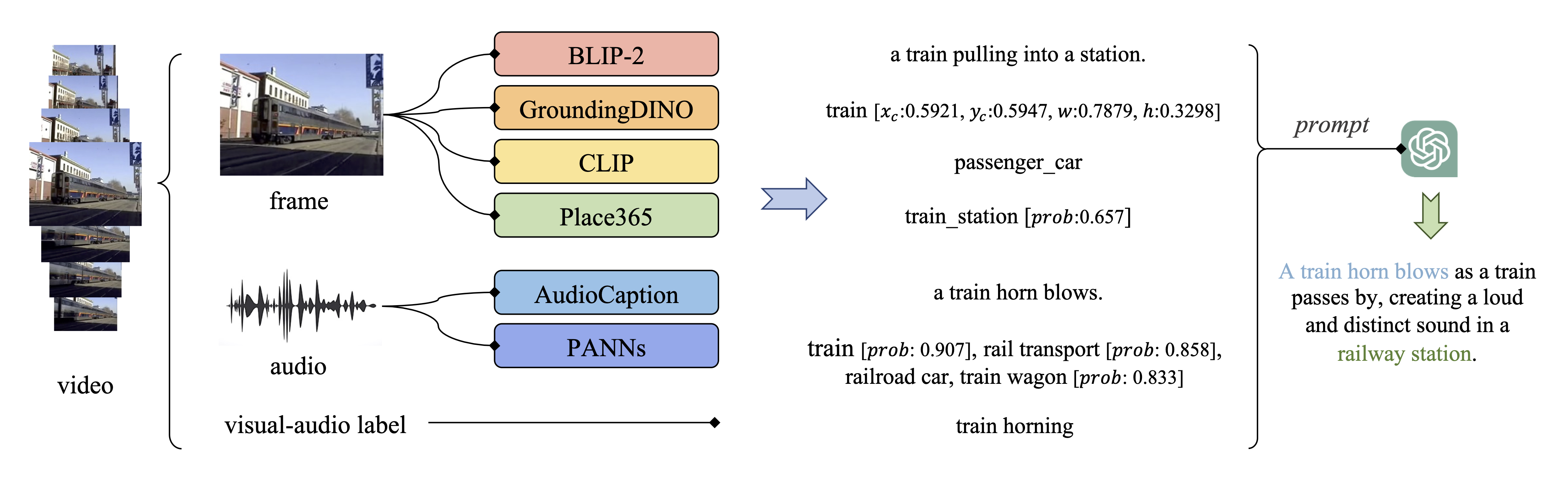
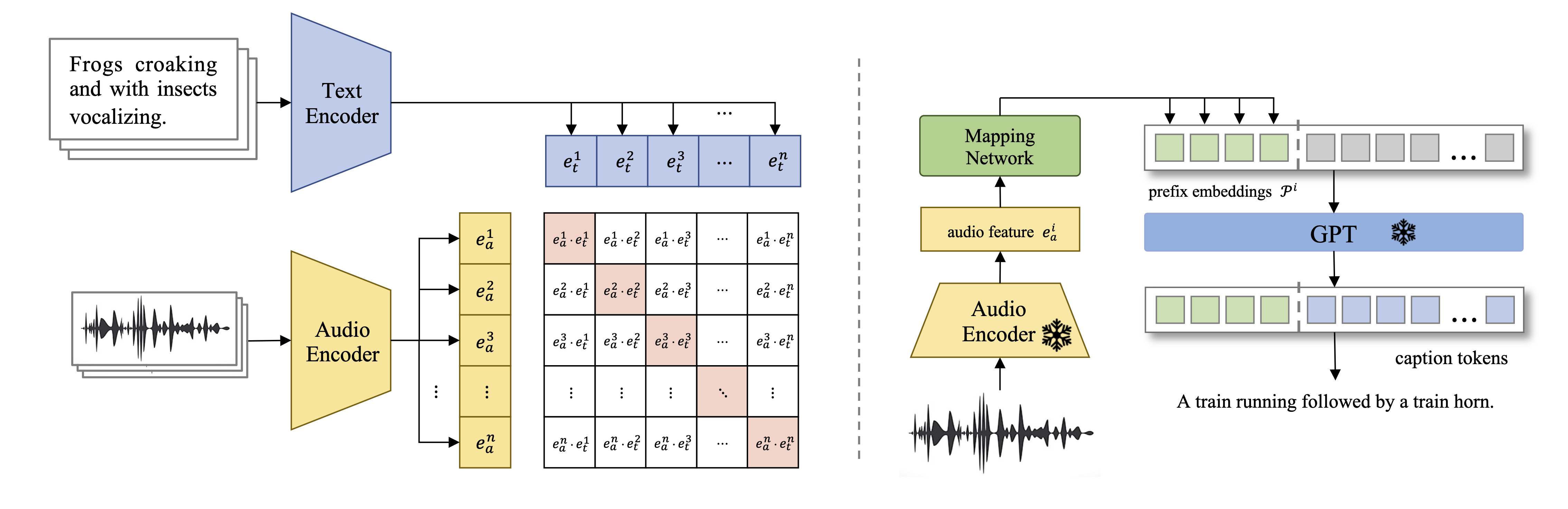

Comparison with CLAP on Clotho and Auto-ACD.
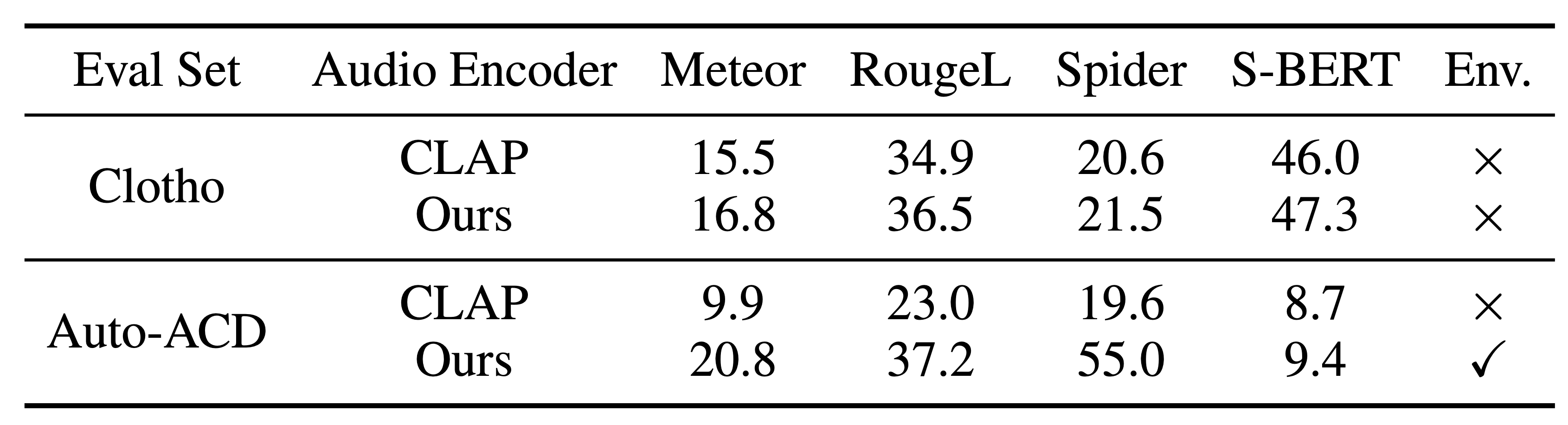
Comparison with CLAP on DCASE 2020 Mobile and AudioSet Env.

Based on a template by Phillip Isola and Richard Zhang.